
검색 관련한 오픈소스 꼽으면 제일 먼저 튀어나오는 ElasticSearch (이하 ES) 와 Solr. 실제로 이 두 개 엔진 모두를 광고 등록과 서빙 과정에서 사용하고 있는데, 각각 어떤 특성을 가지고 있는지 알아보려 한다. 특히 ElasticSearch는 Kibana라는 로그 시각화 툴과도 연관이 있는 것 같은데, 이 둘 간의 관계를 파악하는 것도 이번 글의 목표. 다음 Solr 글에서는 ES와 비교도 해볼 수 있겠다.
그리고 당연히 elastic 하면 이 노래를 안 듣고 갈 수가 없다
ElasticSearch?
ES는 Apache Lucene을 기반으로 설계된 분산 검색 및 분석 엔진이다. 2010년 처음 릴리즈된 이후 로그 분석, full-text search, Business Analyst 등 여러 방면에서 빠르게 보편화되었다.

ElasticSearch의 특징
빠른 속도와 전문(full-text)검색
역색인(Inverted Index) 을 활용해 풀텍스트 검색이 용이하다. 또 문서가 색인되고 검색 가능해질 때까지 1초 가량이 소요되어 준실시간 검색 플랫폼을 제공한다고 한다. 특히 Solr와 비교했을 때의 장점으로 이 준실시간성이 꼽히는 것 같다. (그러나 이 1초라는 게 완전한 실시간성을 지원하는, 다른 NoSQL과 차이를 만들어내는 것 같다. Commit과 Flush 같은 과정들이 있다고 하는데, Lucene의 구조적 특징에 기인한 것으로 보임.)
다국어 지원
색인에는 형태소 분석이 중요하다. 조사나 보어 같은 걸 색인할 이유는 없을 테고, 대소문자를 구별하지 않는 편을 선택할 수도 있을 테니까. 기능별, 언어별 플러그인을 적용할 수 있다. 한국어의 경우 Nori나, 아리랑, 은전한닢 등의 한국어 형태소 분석기 프로젝트들이 있다.
분산처리 & Schemaless
ES에 저장된 문서는 샤드Shard 라고 하는 여러 컨테이너에 걸쳐 분산처리되며, 사본도 생성해 하드웨어 문제로 인한 장애 발생 위험을 줄인다. Scale out도 가능한 구조. 샤드는 논리적이면서 물리적인 색인 단위이고, 각 ES shard는 Lucene Index에 해당한다. Lucene index는 segment라고 불리는 더 작은 파일 단위로 쪼개질 수 있다.
또한 비정형 문서도 색인하고 검색할 수 있기 때문에, 이런 점들은 NoSQL과 비슷하다고 할 수 있겠다.

RESTful API
HTTP 기반의 RESTful API를 지원한다. (RESTful API에 대해서는 나중에 쓸 기회가 있을 것 같다. 대충... 쓰기좋고 보기좋고 여러모로 훌륭한 API란 이런 것이다~를 멋있는 말로 써놓은 것이다) request와 response에 JSON을 활용하기 때문에 개발언어, OS 등에 무관하게 여러 플랫폼에서 활용이 가능하다.
저장소 / 로그시각화 / 랭킹 등의 기능
ElasticSearch의 검색 기능 외에도 아래와 같은 기능을 부분적으로 활용할 수도 있다.
- 역색인과 비정형 데이터 핸들링, 분산처리를 지원하는 유사-NoSQL 저장소의 기능
- Kibana를 이용한 실시간 비정형 로그 데이터 수집 및 통계분석, 시각화
- 또 검색에는 relevance 계산이 필연적이니, ranking 기능을 활용할 수도 있겠다.
특히 Kibana의 경우 "Elastic Stack" 이라 불리는 ElasticSearch, Logstash, Beats, Kibana 조합 중 하나인데, Visualizing / Dashboard 를 지원한다. 가령 ES에 데이터를 집어넣고, 키바나에서 이를 탐색하고 조사하거나 실시간 대시보드를 통해 로그를 분석할 수도 있다. 머신 로그, 센서 측정 데이터 등등을 시각화할 수 있다고 한다. 또 이를테면 검색광고 서버에서 실시간으로 트래픽이 튀거나, 이런 것도 확인할 수 있다는 것.

그리고 ranking에 있어, ElasticSearch는 기본적으로 BM25 알고리즘 (언젠간.. 얘기해볼 수 있을까?) 을 이용해 score를 계산한다. 거기에 function_score 기능 등을 이용해 용도에 맞추어 랭킹을 커스터마이징할 수도 있다. "ES에서 검색 기능은 안 쓰고 랭킹만 써요" 라는 말의 뜻은 이런 거였다!
오픈소스
꽤 많은 지지를 받는 라이브러리이기 때문에, 유지보수 면에서 이점을 가진다.
Apache Lucene?
아래 아저씨를 기억하는가? Hadoop의 아버지 더그 커팅이다.

이 아저씨가 해낸 일이 또 하나 있는데 바로 역색인(Inverted Indexing)에 기반한 Apache Lucene이다. 참고로 Lucene이라는 이름이 더그 커팅 아내의 middle name이자 그의 할머니 이름이라고 하는데, 그러니까 자꾸 이쪽 세계 네이밍에 관심 가질 필요가 없다. java가 커피를 너무 좋아해서 생긴 이름이라느니, 그럼 대체 왜 javascript는 java랑은 아무 관련이 없는건지... 정말 알려고 해봤자 허탈함만 남게 됨.
기본적으로 색인과 검색을 제공하는 라이브러리로, 전문 검색(full text) 및 색인 기능을 필요로 하는 응용 프로그램을 개발하는 데에 적합하다. 색인과 검색 외의 기능 - 이를테면 문서수집(크롤링), 텍스트 추출, 검색서버 등은 제공하지 않거나, 별도의 라이브러리를 사용해야 한다. 아래 그림에서 진하게 표시된 기능만 지원한다는 것.
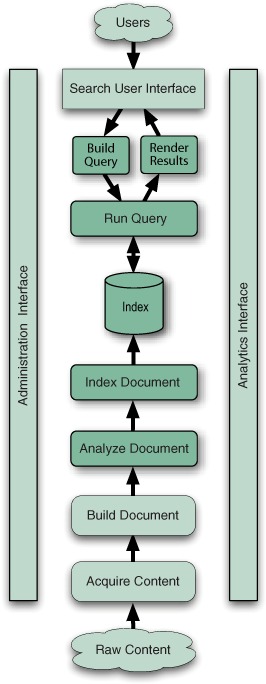
역색인 (Inverted index)
이게 inverted 라는 말 때문에 헷갈리는데, 그냥 쉽게 말해 만들어둔 색인을 재활용하는 거다. 이를테면
"향신료" .... 203pg, 204pg
라고 미리 만들어둔 색인이 있으면, "향신료"를 검색했을 때 쉽게 203, 204pg를 찾아낼 수 있다는 것. 즉, 색인이 문서들에서 키워드를 뽑아내는 과정이라면, 역색인은 키워드에 대해 검색 요청이 들어왔을 때 문서를 반환한다.
일반적인 관계형 데이터베이스에는 단방향 색인을 사용한다. 특정 키워드 (Term) 를 포함하고 있는 문서를 찾기 위해선 모든 문서를 읽어서 키워드의 포함 여부에 대한 검사가 이루어져야 한다. 다시 말해, RDBMS에서 like %검색% 을 수행하면 모든 행을 다 뒤져야 한다.
반면 Apache Lucene은 Inverted File Index를 활용해 색인 구조를 생성한다. Term을 포함하고 있는 문서들에 대한 Primary Key를 매핑하는 index table을 생성하는데, 이 테이블이 있으면 빠른 문서 검색이 가능하다. 이 index table은 BTree, Trie, Hash Table 등의 자료구조를 활용해 구현된다.

이 과정에서 의미 단위의 Term을 뽑아내기 위해 형태소 분석이 필수적이고, 분석기에 따라 대소문자를 정돈한다.
마치며
어쩌다보니 ElasticSearch 그 자체보다는 백본이 되는 Lucene에 대해 더 많이 적은 것 같은데, ES 자체만으로는 별로 얘기할 게 없고 그보다는 태생이 Lucene으로 같은 Solr와 비교함으로서 더 많은 얘기를 할 수 있을 것 같다. 우선은 "역색인"이 이러한 검색 라이브러리의 핵심이 된다는 것 정도를 takeaway로 할 수 있을듯.
아 근데 진짜... 개발 안하면서 개발 얘기 하려니까 너무 어렵다.......;;;
참고
https://aws.amazon.com/opensearch-service/the-elk-stack/what-is-elasticsearch/
https://ko.wikipedia.org/wiki/아파치_루씬
https://velog.io/@koo8624/Database-Elastic-Search-1편-역색인Inverted-Index과-형태소-분석
https://the-dev.tistory.com/30
https://www.skyer9.pe.kr/wordpress/?p=962