
작년 중순이었나, 다방면으로 엄청 열정적인 개발자 분이 NoSQL 전반에 대해 한번 스터디를 진행해주신 적이 있었다. 그 당시 절반도 이해하지 못했어서 좀 난감했는데, 결국 회사 데이터가 적재되고 활용되는 백본을 알아야겠다는 결론에 도달. 원래는 혼자 보려고 노션에 정리하려다가, 회사에선 노션을 쓸 수 없잖아? 개인 홈페이지 등 여러 대안을 생각해보다가 빠른 실행 + 앞으로 누적될 학습을 위해 웹 편집이 가능한 티스토리에 정착했다는 이야기.
Hadoop?
- 아파치 하둡 프로젝트는 신뢰성 있고(reliability), 확장 가능(scalability)한 분산 컴퓨팅을 위한 오픈 소스 소프트웨어이다.
* 아파치: 오픈 소스 소프트웨어 그룹 - 아파치 하둡 소프트웨어 라이브러리는 간단한 프로그래밍 모델을 이용해 (컴퓨터들의) 클러스터 전반에 존재하는 대용량 데이터셋의 분산처리를 가능하게 하는 프레임워크이다.
- 한 개부터 몇 천 개의 서버로 스케일-업 할 수 있도록 디자인되어 있고, 로컬 컴퓨테이션과 스토리지를 제공한다.
- 고가용성(high-availability, 서버와 네트워크, 프로그램 등의 정보 시스템이 상당히 오랜 기간 동안 지속적으로 정상 운영이 가능한 성질)의 하드웨어에 의존하는 게 아니라, 어플리케이션 레이어에서 오류를 감지하고 처리할 수 있도록 라이브러리가 디자인되어 있어 (단일 컴퓨터에서 오류에 취약한 것 대비) 클러스터 상에서 고가용성을 제공할 수 있다.
Hadoop의 코어근육
- Hadoop Common - Common

Common은 Common 딘딘은 딘딘 - Hadoop MapReduce - MapReduce에 관해서는 별도 문서를 참고. Splits, Mapping 을 담당하는 map과 Shuffling, Reducing을 담당하는 reduce의 조합
-
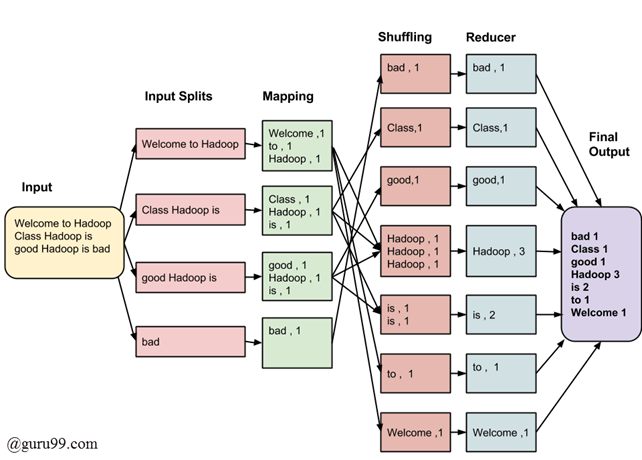
source: guru99.com
-
- Hadoop Distributed File System (HDFS) : 1) 고성능이 아닌 일반 하드웨어로 구성된 클러스터에서 실행되며 2) 대용량 파일을 핸들링하도록 설계된 파일 시스템.
- 파일 블록 (대체로 128MB의 블록인데, 데이터가 적으면 그보다 작은 용량을 차지) 단위로 쪼개서 저장3 Replication Factor로 각 블록의 복제본을 3개 생성하고, 다른 서버에 배치
- 두 가지의 핵심 컴포넌트인 namenode나 datanode에 대한 내용도 있지만, 여기선 생략
- Hadoop YARN: mapReduce의 차세대 버전
Hadoop Ecosystem
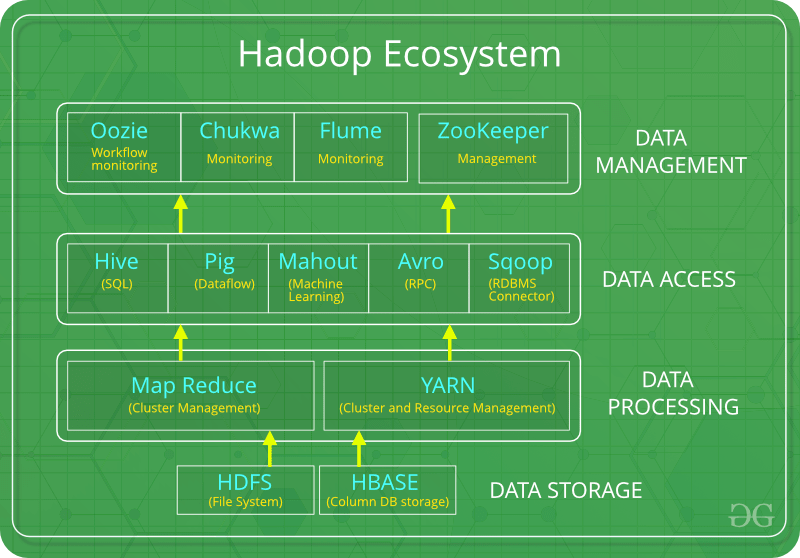
찾아낸 도표 중에선 가장 깔끔하다. 스토리지 - 프로세싱 - 액세스(추출) - 매니징 관점에서 사용되는 툴들이 있는데, 오늘 다룬 메인 주제인 HDFS와 Map Reduce가 어느 정도에 위치하고 있는지 잘 보인다.
Product Manager로서 Hadoop과의 접점은 Data Access 단 정도부터였다. 회사에서도 Hive로 데이터 추출을 하고 있다. 그래서 SQL과 유사하지만 다른 문법인 HQL(Hive Query Language)로 검색을 해야 정확함. 데이터 추출에 Pig도 사용할 수 있는 것 같은데, Hive와 Pig를 비교한 건 이 문서에서 잘 다루고 있다. 아무래도 보편적인 sql문으로 쉽게 접근 가능하단 점이 플러스 요인 아닐지.
여담
하둡이 왜 노란 코끼리인지 궁금하다 했지. 창시자 중 한 명인 Doug Cutting의 아들내미가 Hadoop이라는 이름을 붙여서 가지고 놀던 노란 코끼리 인형에서 따왔다고 한다.

참고 / 번역 원문:
https://www.guru99.com/introduction-to-mapreduce.html
https://mr-devlife.com/all-about-hdfs-concept/
https://www.geeksforgeeks.org/hadoop-ecosystem/
'Data' 카테고리의 다른 글
| Apache Kafka 카프카 (4) | 2022.05.01 |
|---|---|
| OLAP과 OLTP (1) | 2022.02.09 |
| xml과 json (8) | 2022.02.01 |


