"olap 으로 말려있으니까 거기서 필요한 거 꺼내 보시면 돼요"
"olap이 뭐에요?"
"아 그 olap 큐브라고 되어있는거요"
"...그래서 olap이 뭔데요?"
"..."
일단 두 가지가 있다. oltp와 olap. 근데 또 비슷하게 생겨가지고는 동의어도 반의어도 아니라는 게 이 글을 한 데 묶는 걸 어렵게 만들었지만, 원래 비슷하게 생긴 게 제일 헷갈리는 거니까 묶어도 되지 않을까. 결론만 놓고 보면 둘 다 비즈니스를 돌아가게 하는 상보적인 축이니까.
OLAP Online Analytical Processing
의사결정 지원 시스템. 2차원 중심인 데이터베이스가 아닌, 실제 의사분석에 필요한 다차원 분석을 가능하게 한다. 따라서 OLAP 시스템의 이용자는 BI 부서, 데이터 분석이 필요한 상품 부서 등이 된다.
OLAP Cube
OLAP을 OLAP이게 하는 핵심. 빠르게 다차원 데이터를 질의하고 분석할 수 있도록 한다. 데이터 볼륨이 커질수록 속도와 효율성이 떨어지는 row-by-column 2차원 테이블인 RDB에 비해 대용량 데이터의 분석에 강점을 가지고 있다. 이를테면 region이라는 단위의 분석에서 시도 / 시군구 / 읍면동 이런 식으로 drill-down이 가능할 뿐 아니라 기간도 연/분기/월 등의 단위로 나누어, 이들을 자유롭게 조합할 수 있다는 개념. drill-down 뿐 아니라 아래 여러 개념을 포괄한다.
Drill-Down: 가령, "시간" dimension에서 quarter, month 단위로 세분화할 수 있다.
Roll-up: 가령, 읍면동별 데이터를 시군구 단위로 "말아올릴" 수 있다.
Slice and Dice: cube를 dimension(s)로 쪼개어 sub-cube 단위로 분석하겠다는 의도.
Pivot: 엑셀의 피벗과 비슷하지만 더 빠르게 다차원의 데이터를 다양한 측면에서 분석 가능

OLTP OnLine Transaction Processing
transaction 중심 어플리케이션을 관리하는 정보 시스템의 한 계열이다. 웹에서 일어나는 transaction을 예를 들자면 뱅킹, atm, 티켓 예매, 문자 전송, 비밀번호 변경, 쇼핑카트의 책을 구매하는 행위 같은 것들이다. 따라서 OLTP 시스템의 이용자는 매장 캐셔, 인터넷뱅킹 사용자 등이다. 실시간으로 많은 transaction을 가능케 해야 하고, ACID 프로토콜을 따르는 RDBMS를 기반으로 한다.
transaction
"데이터에 대한 하나의 논리적 실행단계"를 의미한다. 가령 은행에서 계좌이체라는 것은 하나의 transaction인데, 구현이 어떤 단계/순서로 이루어지든 결과는 다음과 같아야 한다: 발신인 잔고의 감소, 수신인 잔고의 증가
ACID 프로토콜
짐 그레이에 의해 정의된 "신뢰할 수 있는 transaction"의 원칙이다. RDBMS에서 구현된 네 가지 속성이라고 이해하면 된다. (반면, NoSQL에서는 BASE: Basically Available, Soft state, Eventually consistent 를 속성으로 한다)
Atomicity 원자성: transaction은 부분적으로 실행되거나 중간에 중단되어서는 안 된다. 즉, 계좌이체에서 발신인 잔고만 감소하든가, 수신인 잔고만 증가해서는 안 된다.
Consistency 일관성: transaction의 실행 이후에도 언제나 일관된 데이터베이스여야 한다. 이를테면, 송금 이후 마이너스 잔고가 발생한다면 이는 일관성을 위배한다.
Isolation 독립성: transaction 은 다른 transaction을 간섭하지 않는다. 즉, 송금 작업이 완전히 종료되지 않으면 송금 결과가 반영된 데이터를 반환하지 않는다.
Durability 일관성: transaction의 결과는 영구히 반영된다. 전원 공급이 끊어져도 데이터가 존속한다.
OLAP vs OLTP
vs라고 써놓았지만 사실은 상보적인 관계다. OLTP 시스템(들)에서 쌓인 transaction들이 data warehouse에 적재되고, OLAP 시스템 상에서 데이터 분석을 해 OLTP의 효과성을 증진시킬 수 있는 인사이트를 뽑아내는 것.
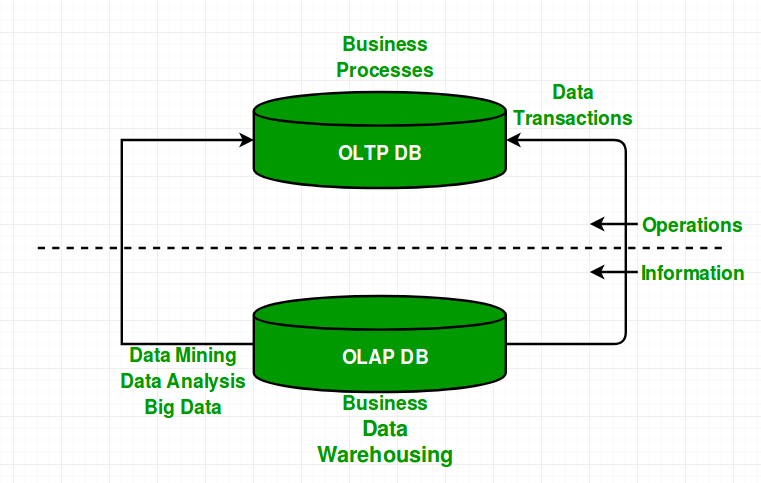
어렵게 갈 것 없이, 편의점 캐셔와 CU의 PM을 생각해보면 된다. 캐셔는 고객이 내미는 신용카드를 받아 단시간 안에 거래를 완료해야만 하고, 이 과정에서는 데이터 적재나 프로세스가 복잡할 리 없다. 단 몇 천 개가 넘을 CU 지점들 모두에서 쌓인 데이터, 또 각 점포가 아니라 창고에서의 입출고 데이터, 이런 것들이 적재되어 PM이 새로운 상품을 출시하려고 할 때 의사결정 토대가 된다는 것.
그 밖의 차이로는 oltp는 읽기/쓰기 모두 잘해야 해서 분산처리.정규화가 중요하고, olap은 읽기 중심이라서 메모리 성능.반정규화가 중요한 것. 등이 있겠다.
출처
https://www.ibm.com/cloud/blog/olap-vs-oltp
https://www.ibm.com/cloud/learn/olap
https://in-harvey-it.tistory.com/10
'Data' 카테고리의 다른 글
| Apache Kafka 카프카 (1) | 2022.05.01 |
|---|---|
| xml과 json (4) | 2022.02.01 |
| Apache Hadoop 하둡 (1) | 2022.01.31 |


